When Written: Aug 2013
Currently I am developing a web application that will work on most mobile devices, this app takes data, filters and analysis it and then presents it to the mobile user in a form that they can use to help make a buying decision. The app calls a web service which interrogates a database of information, all stuff that I have done before. The tricky part with this project, (I always prefer if there is at least one tricky part to a project to make it interesting), is getting the data into the database in the first place. The initial data for testing was captured and imported manually but this is obviously not a solution for the final working product so a way of automating this is required.
The information that is imported is held on several web sites which have given their permission for us to reuse their data. Various ideas were tried including automating the very versatile web import capability of Excel. But I felt that more control over what was imported and the ability to process the values during the import would save on having to run a two-stage process over the data. I had dabbled with the HTML Agility pack add-in to ASP .NET before but it has improved since my first messing about with it. I thought it would be an interesting technique to show here as the documentation is not great and getting the exact syntax was quite tricky.
The idea behind the HTML Agility Pack, which is free, is to make it easy to load an HTML or XML page into your application and then to process that to extract the data. There are other ways of doing this sort of task in code but the idea of this add-in to Visual Studio is to make the code easy. So let’s see what this code looks like and what you have to do to use the add-in.
NuGet is an easy way to install add ins to Visual Studio
Like most add-ins they are available via NuGet (www.nuget.org) which is a repository for all sorts of packages and by using this method of installing a package all the necessary files are coped to your project as well as the relevant references are added as well as config file changes made. This takes a lot of the work out of getting these extensions to work in your development environment and means that you can get coding that bit quicker. Whilst Visual Studio 2013 comes with the NuGet package manger pre-installed, Visual Studio 2010 and 2012 require you to install this manager program via the “Tools|Extensions and Updates”.
Once this is done create a new project of the type you want, in this example I am using a Windows Form application. Then using the “Tools|Library Package Manger|Manage NuGet Packages” search for HtmlAgilityPack. Selecting this will install the HtmlAgility pack into your current project and create the basic ‘wiring’ to enable you to code with this. Before you can call any of the methods that this pack offers, you need to add a reference to it at the top of your class code with either an ‘Imports HtmlAgilityPack’ if you are coding in Visual Basic or a ‘using HtmlAgilityPack;’ if you are coding in C#. Although I decided to build a Windows Form application for this task it could just as easily been a web application, but I wanted easier access to the client machine’s file system which a Windows application would give me as it would run in the security context of the logged in user rather than in the ‘sandbox’ of a browser. Of course one can code around these issues, but why make things complicated for yourself!
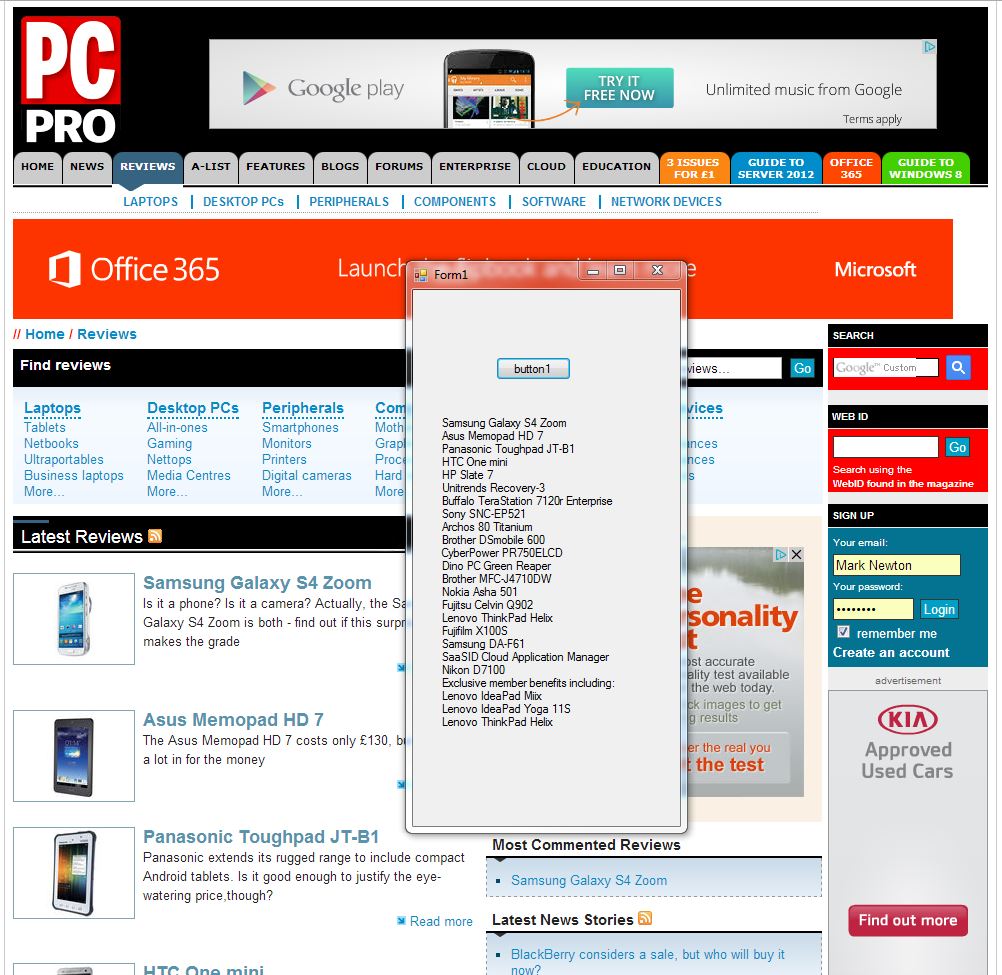
[graphic: PcPro.jpg caption: HtmlAgilityPack makes ‘screen scraping’ easy]
So first we find the URL of the web page that we wish to extract data from, it is a good idea to pick a page, if you can, that has a good structure as you will have to ‘read’ this structure in your code A quick opening of the DOM inspector within the developer tools of most browsers should give you an idea of this. I have chosen the reviews section of the PcPro web site and aim to extract the title of each review. The first two lines of my code are to store this page URL to a variable and then to ‘correct’ this string to a correctly formatted URI so the code looks like this:
string myurl = "http://www.pcpro.co.uk/reviews";
string correctpath = new Uri(myurl).AbsoluteUri;
Next we have to create an object of type HtmlWeb, this will ‘hold’ the contents of the web page’s HTML code, so a simple:
HtmlWeb hw = new HtmlWeb();
This will create an object called ‘hw’ of type ‘HTMLWeb’ and now we use the HtmlAgility pack to load the HTML from our web page into this object with the line:
HtmlAgilityPack.HtmlDocument hdoc = hw.Load(correctpath);
So now we have a second object, this time called ‘hdoc’ with the HTML in it. As the software is going to need a well-structured HTML ( or for that matter XML ) page it is handy to add a line after this code that will attempt to fix any incorrectly nested tags with the line:
hdoc.OptionFixNestedTags = true;
With our nicely tidied up HTML stored in an object we can now start to examine it with the commands available to us via the HtmlAgility pack. These tools use the xpath syntax which is normally used in conjunction with XML data. If you are not familiar with xpath then a quick visit to http://www.w3schools.com/xpath/xpath_syntax.asp should get you started. There is also a useful article at http://martinsikora.com/parsing-html-pages-using-xpath for further reading. Armed with our knowledge of xpath we first look through our captured HTML for the <body> tag which will get us to the correct point to start to examine for the data we want. This code is:
string t = hdoc.DocumentNode.SelectSingleNode("//body").InnerText;
We need a bit of code just to check that all is well in the formatting of the document and we can do this with:
if (hdoc.DocumentNode != null)
{
HtmlAgilityPack.HtmlNode bodyNode = hdoc.DocumentNode.SelectSingleNode("//body");
if (bodyNode != null)
{
And finally we walk through the HTML DOM and in this case we are looking for <h3> tags because this is what identifies the title of each item in the PcPro reviews list that we want to extract.
foreach (HtmlNode node in hdoc.DocumentNode.SelectNodes("//h3"))
{
label1.Text = label1.Text + "\r\n" + node.InnerText; //Build a label to display items
}
Obviously you can look for anything or a combination of things and the code can get complex but from this example I hope you can see that the HtmlAgility pack does make things pretty simple.
Article by: Mark Newton
Published in: Mark Newton